Chapter 1 Introduction
We hope this book provides a gentle introduction to data science. The main goal is to understand how to work with spreadsheet data and how data can be manipulated for multiple purposes. If nothing else, the book hopes to help you plan how to structure your own datasets for your own analysis. Even if you never go on to program on your own, understanding the way data can be manipulated and having a plan for your own dataset in the processing pipeline, will go a long ways when leaning and doing the analysis on your own, and/or working with collegues and collaborators on a project.
1.1 A glossary of terms
The Carpentries have started a multilingual glossary of terms at glossario, to help learn a lot of the technical jargon used in data science and programming. We will try to link to as many of these terms throughout the book. If there is a term that you do not know (or always wanted a more formal definition), you can either contact the book authors and we can help define it for you (and maybe even submit the definition on your behalf)!
1.2 The Learning Process
Programming is hard. Not only is there a steep technical learning curve, but there is a lot of jargon that makes the initial learning curve difficult.
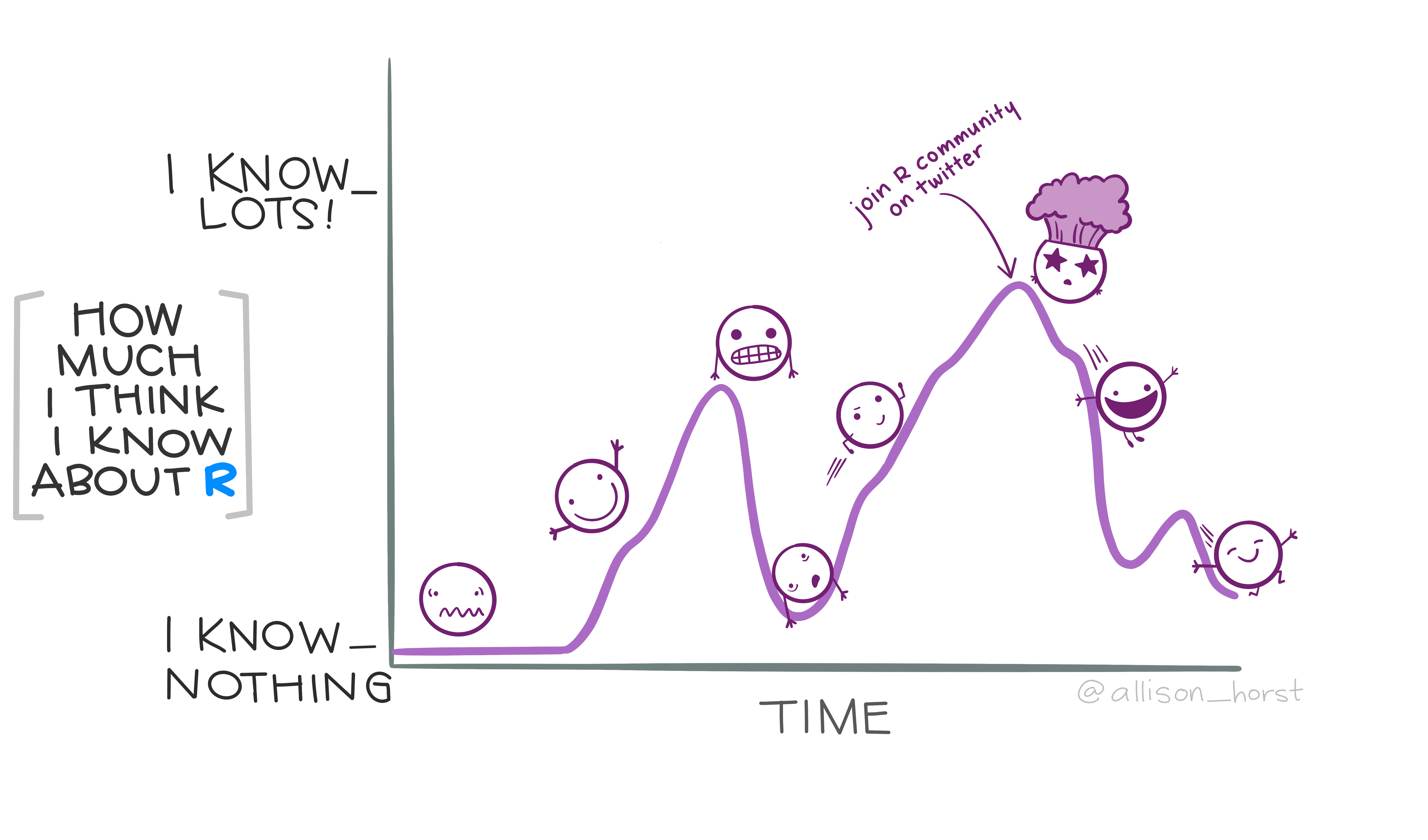
Figure 0.2: “R Rollercoaster” by Allison Horst. There is an initial learning curve when learining how to program. When you get a hang of the first learning curve, you realize there’s much more to learn. You will more skills and join a community, where you will realize you know even less, but that’s okay.
Programming itself involves breaking down your steps into small linear pieces. Do not try to do all of your analysis in a single step. Usually, when you get stuck for a while, a simple walk to clear your head may be all you need to successfully approach the problem.
!["Debugging" by Allison Horst. The 10 stages of debugging (1) I got this. (2) Huh. really thought that was it. (3) ... (4) Fine. Restarting. (5) OH WTF. (6) Zombie meltdown. (7) Sleep exhaustion (8) An idea, a new hope. (9) [insert awesome theme song] (10) I <3 CODING!.](https://raw.githubusercontent.com/allisonhorst/stats-illustrations/master/other-stats-artwork/debugging.jpg)
Figure 0.3: “Debugging” by Allison Horst. The 10 stages of debugging (1) I got this. (2) Huh. really thought that was it. (3) … (4) Fine. Restarting. (5) OH WTF. (6) Zombie meltdown. (7) Sleep exhaustion (8) An idea, a new hope. (9) [insert awesome theme song] (10) I <3 CODING!.
There is a huge community of users, learners, and instructors that all want you to succeed.

Figure 0.4: “Monster Support” by Allison Horst. We believe in you.
The main take away is to learn about formatting your data set, and planning how your data sets may be useful in the future. When you are starting to learn how to program, you do not need to jump into it completely. If this book shows you a technique that makes your data pipeline easier, there is nothing wrong with writing the few lines of code to read in, manipulate, and save out the dataset for something else. Your programming skills will build over time, and there is no need to rush it.

Figure 0.5: “R Frist Then” by Allison Horst. At first I was like … surrendering with a white flag to the R monster … but now it’s like … we’re high fiving under the sun.
1.3 Expectations
The book and workshop series will cover a lot of information. In the first pass of seeing the content, there is no expectation for you to be able to program right away. The materials provided here will be here to serve as a reference when you do plan to start your own data work.
The next time you start putting together a dataset and can think about the next steps (even if you aren’t going to be the one doing the analysis), you have learned enough to manage your data in a productive and collaborative way.
Simply loading a dataset you have, even if you do not do anything with it, will start making the interface less novel and scary.